
Zero-Shot Learning: Teaching AI to Think Beyond Labels
Published:
Machine learning models typically rely on labeled training data to make accurate predictions. But what if an AI model could recognize or classify without ever seeing them before?
That’s where Zero-Shot Learning comes in. My internship experience at a Research Lab has made me realize the cost of creating accurate labels and training data, it takes so much time and resources. By using Zero-Shot Learning you’re able to mitigate the cost of generating labels and make strides in making more-or-less accurate inferences.
It is a method that allows AI models to generalize knowledge to unseen categories without explicit training. In this post, we’ll explore what ZSL is (from my understanding at least), how it works, and how you can apply it in your own projects.
What is Zero-Shot Learning?
Zero-Shot Learning is a machine learning paradigm/technique that enables models to perform tasks without having seen specific examples during training.
It works by mapping inputs to a semantic space, allowing the model to reason about unseen categories using pre-learned knowledge.
Let me clarify with the examples below on the contrasting difference between a traditional model and a zero-shot model.
For example:
- A traditional supervised model, trained only on images of dogs and cats, cannot recognize a tiger unless it’s explicitly included in the dataset.
- A zero-shot model, on the other hand, can recognize a tiger by leveraging semantic relationships, such as:
- “A tiger is a large striped cat.”
- “Tigers belong to the same family as lions and cheetahs.”
- “Tigers are carnivorous animals.”
By understanding these relationships, the model can reason about the tiger even though it has never seen one before.
I hope that makes sense, so lets move on to the three main approaches to Zero-Shot Learning.
Three Approaches to Zero-Shot Learning
There are three main ways that Zero-Shot Learning is implemented in AI:
-
Attribute-Based ZSL – Uses human-defined attributes for example: “a zebra has black and white stripes” to classify unseen objects.
-
Embedding-Based ZSL – Uses pre-trained embeddings e.g Word2Vec, GloVe, CLIP to relate new concepts to known ones.
-
Prompt Engineering for NLP – Uses large language models (LLMs) like GPT-3/BART to classify text without explicit training.
I have interacted with it during Prompt Engineeering for NLP, so thats what we’ll focus on.
Zero-Shot Text Classification Using Facebook’s BART Model
In my projects, I used Facebook’s bart-large-mnli model from Hugging Face to perform Zero-Shot Classification on text data.You can check it out here.
This model is pre-trained for Natural Language Inference (NLI), which allows it to determine how well a given label relates to the input, returning a sort of semantic score on how likely the input maps onto the label.
Here is how you can implement it:
from transformers import pipeline
# Load Zero-Shot Classification Pipeline
classifier = pipeline("zero-shot-classification", model="facebook/bart-large-mnli")
# Example text
text = "The stock market is experiencing a rapid downturn."
# Candidate Labels
labels = ["finance", "sports", "technology", "politics"]
# Perform Zero-Shot Classification
result = classifier(text, labels)
print(result)
How it works:
- Input: “The stock market is experiencing a rapid downturn.”
- Candidate Labels: [“finance”, “sports”, “technology”, “politics”]
- Output: The model assigns a probability score to each label, determining which category best fits the text.
{'sequence': 'The stock market is experiencing a rapid downturn.', 'labels': ['finance', 'technology', 'sports', 'politics'], 'scores': [0.9799144268035889, 0.007895511575043201, 0.006466912105679512, 0.005723180249333382]}
The most relevant category here is finance. While humans can easily infer this, a machine learning model relies on probability scores to make a prediction.
You could print the most relevant label, and thats how you can use zero shot learning to classify text data to predefined category labels.
sorted_results = sorted(zip(result['labels'], result['scores']), key=lambda x: x[1], reverse=True)
# Print the most relevant label
top_label, top_score = sorted_results[0]
print(f"Most Relevant Category: {top_label} ({top_score:.4f})")
Result:
Most Relevant Category: finance (0.9799)
Here is the probability distribution of the labels, just observe the fact the data is highly skewed to finance.
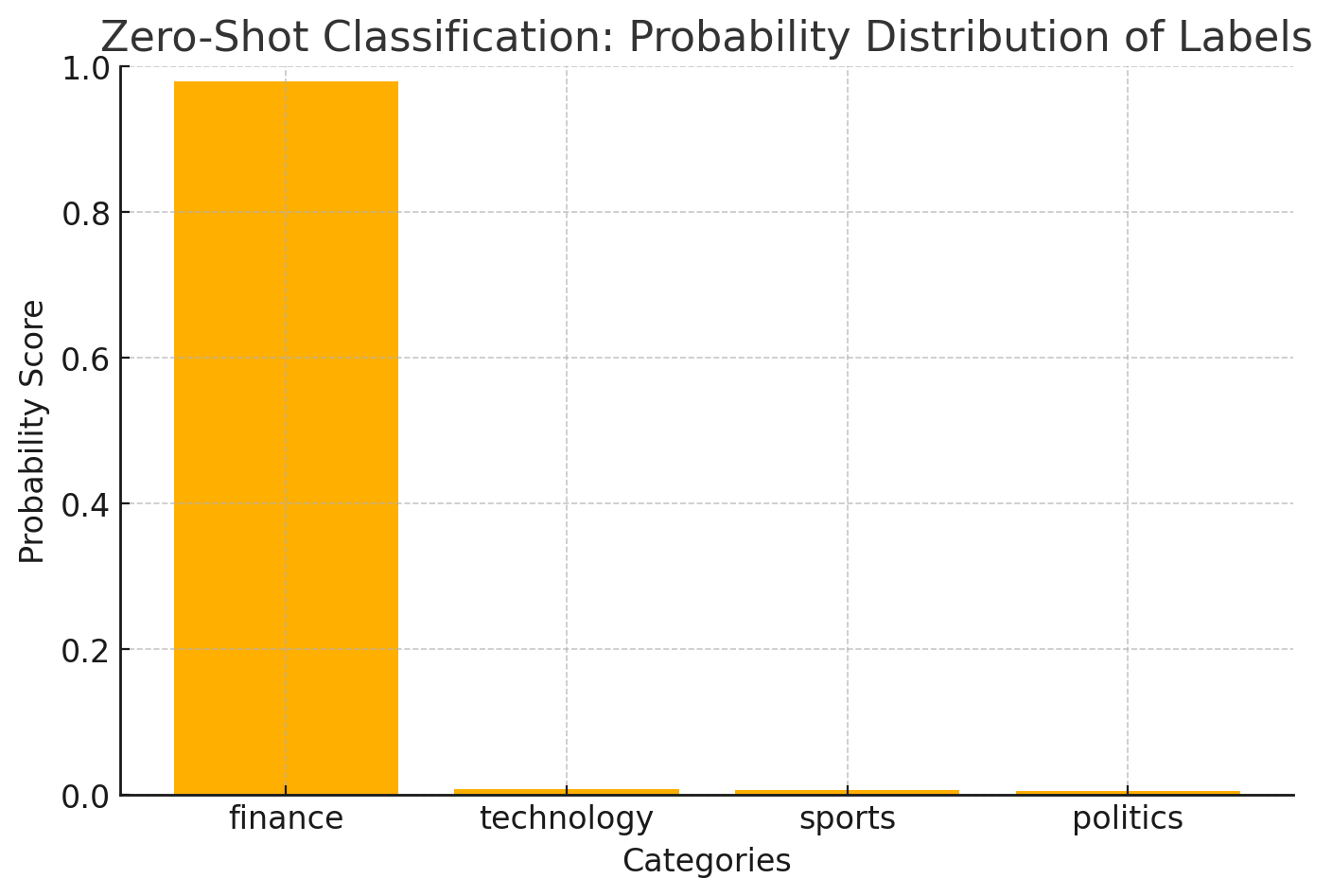
You could decide to exclude the probability score, to make it more semantically appealing, without the score. by removing this section ({top_score:.4f})
Most Relevant Category: finance
And there you go you’ve been able to classify the text and assign it an appropriate label without the need of training data
I recently worked on an AI News Aggregator for an AI hackathon in a team of 4 and we had such a limited time to work with. We managed to streamline our work by using Zero-Shot Learning and we were able to categorize the news text drawn from web-scraped information by predefining labels that would essentially map the news text to an appropriate label. You can check out the GitHub repository here.
Using Zero-Shot Learning significantly reduced training overhead and implementation costs.
Challenges and Limitations of Zero-Shot Learning
While Zero-Shot Learning is an incredibly powerful approach, it comes with its own set of challenges that limit its effectiveness. Here are some key drawbacks:
1. Lower Accuracy Compared to Supervised Models
Since ZSL models have never seen the specific categories before, their performance is often weaker compared to supervised models trained with labeled data.
- If the semantic relationships are weak or unclear, the model may misclassify the data.
- Example: If you ask the model to classify “Quantum computing is the future.” with labels like [“science”, “finance”, “politics”], it might struggle to assign the most accurate category.
2. Sensitivity to Label Choices
- The quality of predefined labels heavily influences performance.
- If the candidate labels overlap in meaning, the model might assign incorrect probabilities.
- Example: A news classification model might confuse “politics” and “government”, or “health” and “medicine” if labels are not well-defined. So basically define your labels well.
3. Bias in Pre-Trained Models
- ZSL models inherit biases from the pre-trained embeddings they use.
- If a pre-trained language model has been exposed to biased data, it may reflect those biases in its predictions.
- Example: A model might incorrectly associate certain professions with specific genders due to biased training data.
4. Struggles with Complex Reasoning
- Zero-Shot models lack deep domain knowledge and struggle with nuanced or multi-faceted topics.
- Example: If you ask “Should we increase interest rates?”, the model may not understand the economic implications, since it has no explicit financial training.
5. Not Always Reliable for High-Stakes Applications
- In critical applications like healthcare or legal analysis, ZSL might produce unreliable results.
- Human verification is often required to ensure accuracy before using the model’s output.
My overall thoughts
Despite all these limitations mentioned, Zero-Shot Learning is still a valuable tool for scenarios where:
- Labeled data is scarce or unavailable.
- If the model is used for low-stakes tasks like categorizing text.
By combining ZSL with Few-Shot Learning or fine-tuning techniques, you can improve the accuracy and reliability of the model. the possibilities here are endless.
While it’s not a silver bullet, ZSL is revolutionizing AI applications by enabling models to generalize better, reduce costs, and accelerate deployment.
What are your thoughts on Zero-Shot Learning?
Thank you for reading the blog 🙏 , till next time.